Example usage
To use mds_2025_helper_functions in a project:
Imports
from mds_2025_helper_functions.scores import compare_model_scores
from sklearn.datasets import load_iris, load_diabetes
from sklearn.dummy import DummyRegressor, DummyClassifier
from sklearn.tree import DecisionTreeRegressor, DecisionTreeClassifier
import warnings
warnings.filterwarnings('ignore')
Compare CV scores of multiple models
compare_model_scores() is a wrapper function for scikit learn’s cross_validate() that allows you to compare the mean cross validation scores across multiple models. The only difference in calling this function compared to cross_validate() is that it takes multiple model objects rather than one.
Note: The default scoring metric is R² for regression and accuracy for classification tasks.
Basic usage
To demonstrate, let’s load a sample dataset and instantiate our model classes. We’ll be using the Diabetes dataset from scikit learn. The Diabetes dataset contains 10 baseline variables and progression of diabetes after one year. To learn more about this dataset, visit its documentation: https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset
X, y = load_diabetes(return_X_y=True)
dummy_regressor = DummyRegressor()
tree_regressor = DecisionTreeRegressor()
This is already enough for our basic use of the function. Simply pass these to compare_model_scores().
Note: The default scoring metric is R² for regression tasks. Negative R² scores indicate the model performs worse than predicting the mean value.
compare_model_scores(dummy_regressor, tree_regressor, X=X, y=y)
| fit_time | score_time | test_score | |
|---|---|---|---|
| model | |||
| DummyRegressor | 0.000114 | 0.000162 | -0.027506 |
| DecisionTreeRegressor | 0.001786 | 0.000196 | -0.175689 |
As you can see, the function returns a dataframe with the performance statistics for each model. The model names are used for the index.
Using cross_validate() arguments
Like cross_validate, the function also works for classification models, and you can pass arguments to reutrn training scores, or use different scoring metrics.
For classification, we’ll be using the Iris dataset from scikit learn. The Iris dataset contains measurements of iris flowers with 3 different species. To learn more about this dataset, visit its documentation: https://scikit-learn.org/stable/datasets/toy_dataset.html#iris-dataset
X, y = load_iris(return_X_y=True)
dummy_classifier = DummyClassifier()
tree_classifier = DecisionTreeClassifier()
scoring_metric = "f1_macro" # A scoring metric for multiclass classification
compare_model_scores(dummy_classifier, tree_classifier, X=X, y=y, return_train_scores=True, scoring=scoring_metric)
| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| model | ||||
| DummyClassifier | 0.000093 | 0.000614 | 0.166667 | 0.166667 |
| DecisionTreeClassifier | 0.000246 | 0.000511 | 0.966583 | 1.000000 |
Passing multiple models of the same type
When you compare several models of the same type, each model is be given an index in the output table based on the order it was passed to compare_model_scores().
second_tree_classifier = DecisionTreeClassifier(max_depth=3)
compare_model_scores(tree_classifier, second_tree_classifier, X=X, y=y)
| fit_time | score_time | test_score | |
|---|---|---|---|
| model | |||
| DecisionTreeClassifier | 0.000306 | 0.000197 | 0.966667 |
| DecisionTreeClassifier_2 | 0.000221 | 0.000153 | 0.960000 |
Perform exploratory data analysis (EDA)
The perform_eda function provides a comprehensive exploratory data analysis (EDA) framework for any dataset. It combines summary statistics and feature visualizations, making it a valuable tool for understanding and exploring data.
Function Signature
perform_eda(dataframe, rows=5, cols=2)
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
dataframe |
|
Required |
Input dataset for EDA. Must be a Pandas DataFrame. |
rows |
|
|
Number of rows in the grid layout for visualizations. |
cols |
|
|
Number of columns in the grid layout for visualizations. |
Returns
This function does not return a value. Instead, it:
Prints a summary of the dataset.
Generates plots for missing values, correlations, and feature distributions.
Outputs potential outliers and scatterplots for numeric features.
Key Features
Dataset Overview
Prints dataset structure, number of rows/columns, and column data types.
Basic Statistics
Descriptive statistics for all numeric and categorical columns.
Handles datasets with mixed data types.
Missing Values Report
Highlights columns with missing values.
Displays a heatmap of missing data if applicable.
Correlation Heatmap
For numeric columns, it computes and visualizes pairwise correlations.
Dynamic Feature Visualizations
Automatically generates appropriate visualizations:
Histograms and KDE plots for numeric features.
Count plots for categorical features.
Line plots for datetime features.
Scatterplots
Scatterplots for numeric feature pairs (if more than one numeric column exists).
Outliers Detection
Identifies potential outliers using the Interquartile Range (IQR) method.
Example Usage
Dataset
import pandas as pd
import numpy as np
np.random.seed(42)
data = {
'age': np.random.randint(20, 60, size=50), # Random ages between 20 and 60
'salary': np.random.randint(30000, 120000, size=50), # Salaries between 30k and 120k
'department': np.random.choice(['HR', 'Finance', 'IT', 'Marketing', 'Operations'], size=50), # Random departments
'joining_date': pd.to_datetime(np.random.choice(pd.date_range('2010-01-01', '2022-01-01'), size=50)), # Random dates
'experience': np.random.randint(1, 30, size=50), # Years of experience between 1 and 30
'performance_score': np.random.uniform(1, 5, size=50), # Performance score between 1 and 5
'bonus': np.random.choice([True, False], size=50, p=[0.3, 0.7]) # Random True/False for bonuses
}
df = pd.DataFrame(data)
Run perform_eda
from mds_2025_helper_functions.eda import perform_eda
perform_eda(df, rows=3, cols=3)
===== Dataset Overview =====
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50 entries, 0 to 49
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 50 non-null int64
1 salary 50 non-null int64
2 department 50 non-null object
3 joining_date 50 non-null datetime64[ns]
4 experience 50 non-null int64
5 performance_score 50 non-null float64
6 bonus 50 non-null bool
dtypes: bool(1), datetime64[ns](1), float64(1), int64(3), object(1)
memory usage: 2.5+ KB
None
===== Basic Statistics =====
count unique top freq mean \
age 50.0 NaN NaN NaN 39.04
salary 50.0 NaN NaN NaN 77464.08
department 50 5 Operations 12 NaN
joining_date 50 NaN NaN NaN 2016-06-11 07:12:00
experience 50.0 NaN NaN NaN 14.74
performance_score 50.0 NaN NaN NaN 3.370538
bonus 50 2 False 31 NaN
min 25% \
age 21.0 30.0
salary 31016.0 53510.25
department NaN NaN
joining_date 2010-07-17 00:00:00 2013-10-28 00:00:00
experience 1.0 7.0
performance_score 1.072301 2.521356
bonus NaN NaN
50% 75% \
age 40.0 46.75
salary 78587.0 99000.0
department NaN NaN
joining_date 2016-01-08 12:00:00 2019-06-17 00:00:00
experience 16.0 23.0
performance_score 3.341115 4.399446
bonus NaN NaN
max std
age 59.0 11.347858
salary 119812.0 27874.066306
department NaN NaN
joining_date 2021-09-22 00:00:00 NaN
experience 29.0 9.222444
performance_score 4.978202 1.080807
bonus NaN NaN
===== Missing Values Report =====
Series([], dtype: int64)
No missing values in the dataset.
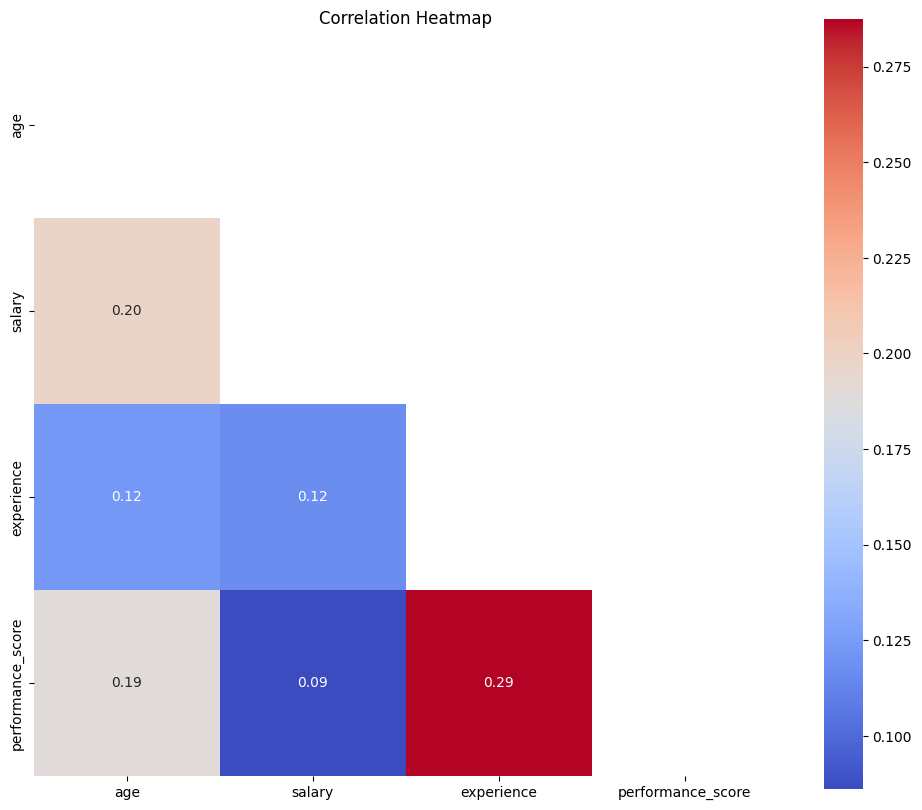
===== Feature Visualizations =====
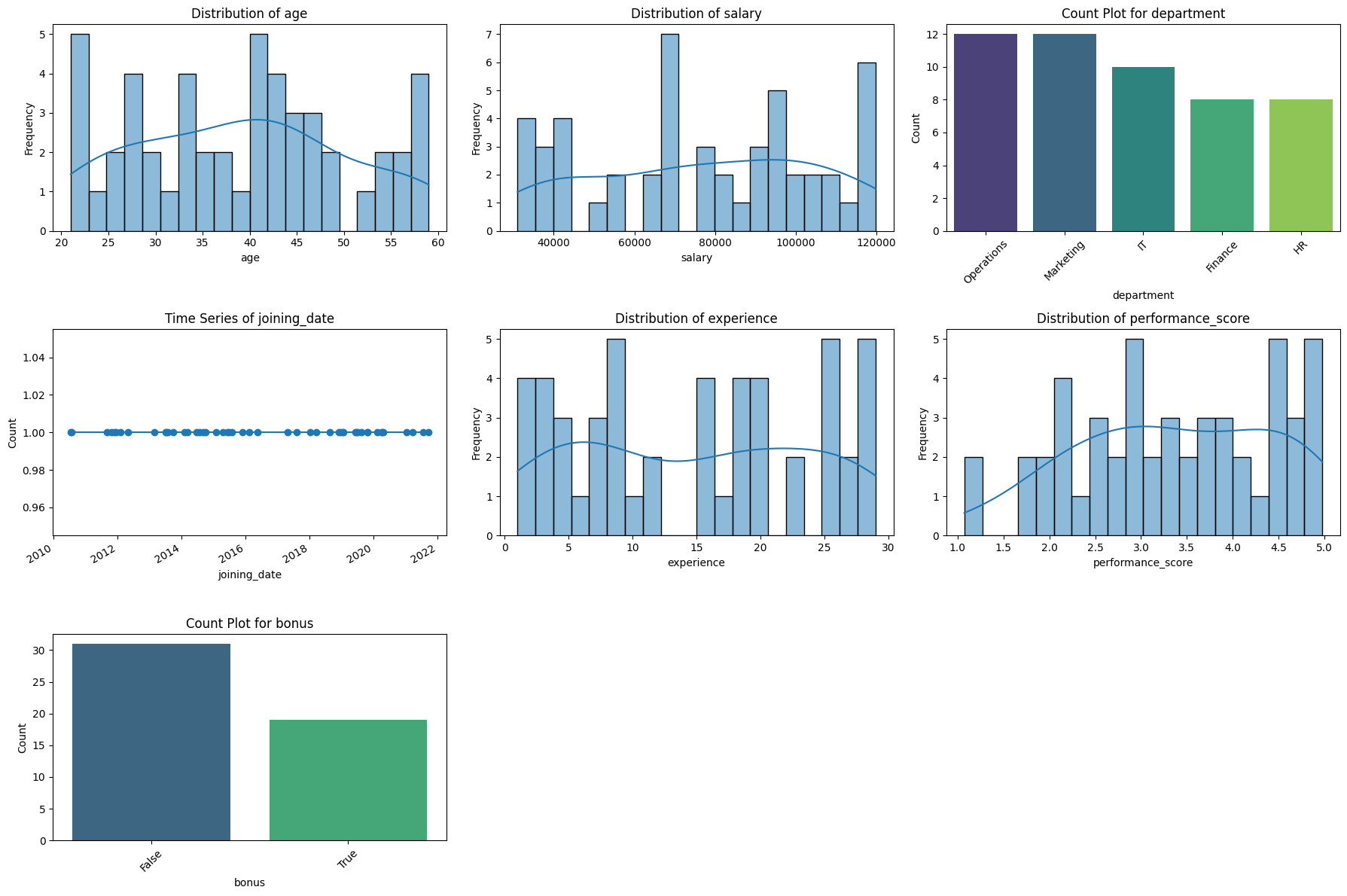
===== Scatterplots for Numeric Features =====
===== Outliers Report =====
age: 0 potential outliers
salary: 0 potential outliers
experience: 0 potential outliers
performance_score: 0 potential outliers
Summarize a dataset
The dataset_summary function provides a comprehensive summary of any dataset. It is designed to give a quick yet detailed overview of the dataset, focusing on missing values, feature types, duplicate rows, and descriptive statistics for both numerical and categorical features.
Function Signature
dataset_summary(data)
Parameters
data
Type:
pd.DataFrameDefault: Required
Description:
Input dataset to analyze and summarize.
Must be a Pandas DataFrame.
Supports both single-index and multi-index DataFrames (automatically flattened for processing).
Sparse DataFrames are supported and converted to dense format during analysis.
Returns
The function returns a dictionary containing the following keys:
Key |
Type |
Description |
|---|---|---|
|
|
A DataFrame summarizing the number and percentage of missing values. |
|
|
Counts of numerical and categorical features: |
|
||
|
|
The number of duplicate rows in the dataset. |
|
|
Descriptive statistics for numerical features. |
|
|
Unique value counts for categorical features. |
Example Usage
Imports and Dataset
We use the Titanic dataset from the seaborn library for this demonstration. First, we import the necessary libraries and load the dataset.
import seaborn as sns
from mds_2025_helper_functions import dataset_summary
# Load the Titanic dataset
titanic = sns.load_dataset("titanic")
# Display the first few rows of the dataset
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
Execute dataset_summary functioin
To start, we pass the Titanic dataset to the dataset_summary function. This generates a detailed summary that includes missing values, feature types, duplicate rows, and summaries for numerical and categorical features.
from mds_2025_helper_functions.dataset_summary import dataset_summary
# Generate the dataset summary
summary = dataset_summary(titanic)
Analyze the Results
Missing Values
The function identifies missing values in each column, providing counts and percentages.
print("Missing Values:")
print(summary["missing_values"])
Missing Values:
column missing_count missing_percentage
0 survived 0 0.000000
1 pclass 0 0.000000
2 sex 0 0.000000
3 age 177 19.865320
4 sibsp 0 0.000000
5 parch 0 0.000000
6 fare 0 0.000000
7 embarked 2 0.224467
8 class 0 0.000000
9 who 0 0.000000
10 adult_male 0 0.000000
11 deck 688 77.216611
12 embark_town 2 0.224467
13 alive 0 0.000000
14 alone 0 0.000000
Feature Types
The summary includes counts of numerical and categorical features in the dataset.
print("Feature Types:")
print(summary["feature_types"])
Feature Types:
{'numerical_features': 6, 'categorical_features': 9}
Duplicate Rows
The function identifies the total number of duplicate rows in the dataset.
print("Duplicate Rows:")
print(summary["duplicates"])
Duplicate Rows:
107
Numerical Summary
The numerical_summary key contains descriptive statistics for all numerical features in the dataset.
print("Numerical Summary:")
print(summary["numerical_summary"])
Numerical Summary:
count mean std min 25% 50% 75% max
survived 891.0 0.383838 0.486592 0.00 0.0000 0.0000 1.0 1.0000
pclass 891.0 2.308642 0.836071 1.00 2.0000 3.0000 3.0 3.0000
age 714.0 29.699118 14.526497 0.42 20.1250 28.0000 38.0 80.0000
sibsp 891.0 0.523008 1.102743 0.00 0.0000 0.0000 1.0 8.0000
parch 891.0 0.381594 0.806057 0.00 0.0000 0.0000 0.0 6.0000
fare 891.0 32.204208 49.693429 0.00 7.9104 14.4542 31.0 512.3292
Categorical Summary
Unique value counts for all categorical features are summarized under the categorical_summary key.
print("Categorical Summary:")
print(summary["categorical_summary"])
Categorical Summary:
column unique_values
0 sex 2
1 embarked 3
2 class 3
3 who 3
4 deck 7
5 embark_town 3
6 alive 2
Comparing Multiple Datasets
The function can be used to analyze and compare multiple datasets simultaneously. Let’s compare the Titanic dataset with the Iris dataset from seaborn.
# Load another dataset
iris = sns.load_dataset("iris")
# Generate summaries for both datasets
titanic_summary = dataset_summary(titanic)
iris_summary = dataset_summary(iris)
# Compare numerical feature summaries
print("Titanic Numerical Summary:")
print(titanic_summary["numerical_summary"])
print("\nIris Numerical Summary:")
print(iris_summary["numerical_summary"])
Titanic Numerical Summary:
count mean std min 25% 50% 75% max
survived 891.0 0.383838 0.486592 0.00 0.0000 0.0000 1.0 1.0000
pclass 891.0 2.308642 0.836071 1.00 2.0000 3.0000 3.0 3.0000
age 714.0 29.699118 14.526497 0.42 20.1250 28.0000 38.0 80.0000
sibsp 891.0 0.523008 1.102743 0.00 0.0000 0.0000 1.0 8.0000
parch 891.0 0.381594 0.806057 0.00 0.0000 0.0000 0.0 6.0000
fare 891.0 32.204208 49.693429 0.00 7.9104 14.4542 31.0 512.3292
Iris Numerical Summary:
count mean std min 25% 50% 75% max
sepal_length 150.0 5.843333 0.828066 4.3 5.1 5.80 6.4 7.9
sepal_width 150.0 3.057333 0.435866 2.0 2.8 3.00 3.3 4.4
petal_length 150.0 3.758000 1.765298 1.0 1.6 4.35 5.1 6.9
petal_width 150.0 1.199333 0.762238 0.1 0.3 1.30 1.8 2.5
Visualize hypothesis tests
We’ll continue to demonstrate the functionality of htv() using the toy data created in perform_eda(),
from mds_2025_helper_functions.htv import htv
df.head()
| age | salary | department | joining_date | experience | performance_score | bonus | |
|---|---|---|---|---|---|---|---|
| 0 | 58 | 97121 | Operations | 2013-09-25 | 6 | 3.801431 | False |
| 1 | 48 | 99479 | Finance | 2015-06-05 | 16 | 4.386645 | False |
| 2 | 34 | 119475 | Finance | 2014-07-22 | 29 | 4.425297 | False |
| 3 | 27 | 49457 | HR | 2014-03-10 | 3 | 2.618033 | False |
| 4 | 40 | 96557 | Marketing | 2015-08-01 | 20 | 4.551080 | True |
Based on our observations of the data, we can set up our hypothesis testing question as Are the average salaries of employees in the research department (e.g., HR) significantly higher than the average salaries of employees in all departments? The hypothesis test will be set as one-tail z-test with significant level a=0.05
Hypothesis (H0): Average salary of departmental HR ≤ average salary of all departments
Alternative hypothesis (H1): Average salary of departmental HR > average salary of all departments
# Extracting relevant data for hypothesis testing
all_salary = df['salary'] # All department salaries
hr_salary = df[df['department'] == 'HR']['salary'] # Salaries for HR department
# Calculating parameters
mu0 = all_salary.mean() # Overall mean salary
mu1 = hr_salary.mean() # Mean salary for HR
sigma = all_salary.std() # Using overall standard deviation as an approximation
sample_size = len(hr_salary) # Sample size for HR
# Define test parameters
test_params = {
"mu0": mu0,
"mu1": mu1,
"sigma": sigma,
"sample_size": sample_size
}
# Visualize hypothesis testing using the htv function
fig, ax = htv(test_output=test_params, test_type="z", alpha=0.05, tail="one-tailed")
(mu0, mu1, sigma, sample_size) # Display the calculated values
(77464.08, 67306.75, 27874.066306200268, 8)
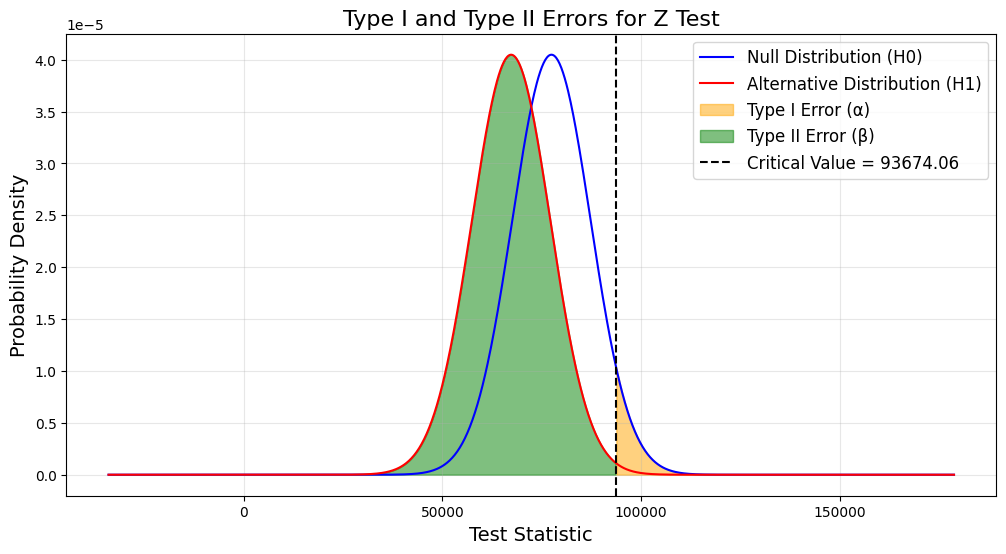
We can clearly see the type1 error and type2 error from the above figure, which provides image help to those who can’t understand the hypothesis test quickly to make them understand.